
Kevin Wang
I am a PhD student at the University of Texas at Austin, advised by Prof. Atlas Wang in the VITA group.
My research centers on agentic AI, verifiable learning, and continual learning. My goal is to design agents that maintain persistent memory and improve themselves over time, with the goal of building autonomous decision-making systems that can explore, learn, and reliably deploy to unfamiliar environments, while scaling in a way we can formally verify.
I’ve also been collaborating with Prof. Sewoong Oh frorm University of Washington and Prof. Pramod Viswanath from Princeton University on multi-agent in game.
News
- Mar 2026 Selected as Qualcomm Innovation Fellowship finalist.
- Feb 2026 VLM-3R accepted to CVPR 2026.
- Jan 2026 Neurosymbolic LoRA accepted as Oral at AAAI 2026 NeusymBridge Workshop.
- Dec 2025 Presented MindGames and SPIN-Bench at Open AGI Symposium and hosted the MindGames competition at NeurIPS 2025 — great to meet all the teams!
- Nov 2025 Had a detour on a startup idea and interviewed at YC — a great short journey!
- Jul 2025 2 papers accepted to COLM 2025: SPIN-Bench and SWIFT.
- Jul 2025 Leading organization of MindGames, a NeurIPS competition for multi-agent LLM.
- Jun 2025 VideoLifter received Best Paper Award at CVPR 2025 AI4CC Workshop.
Selected Publications
* denotes equal contribution
|
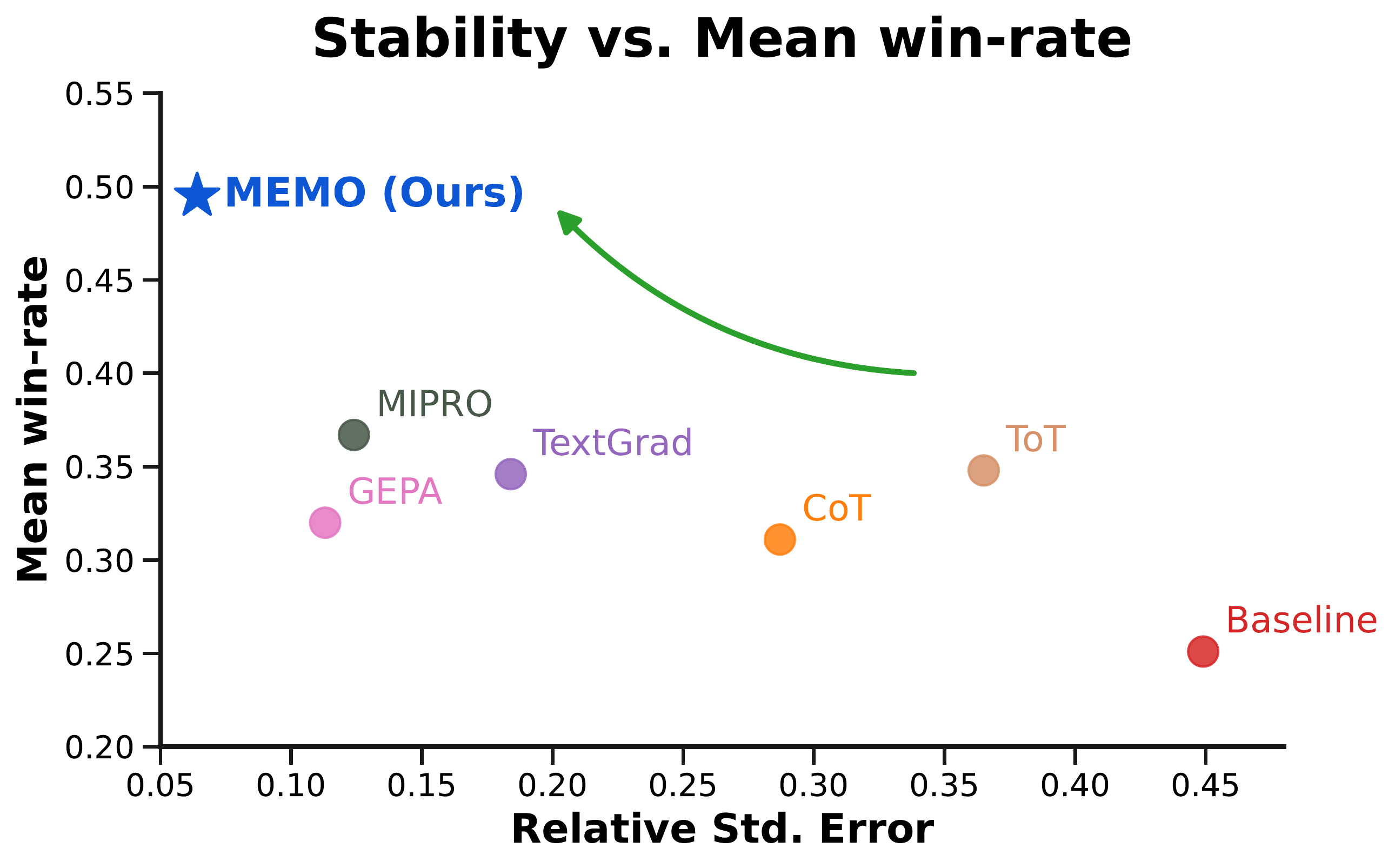
Preprint 2026
|
|
CVPR 2026
|
|
|
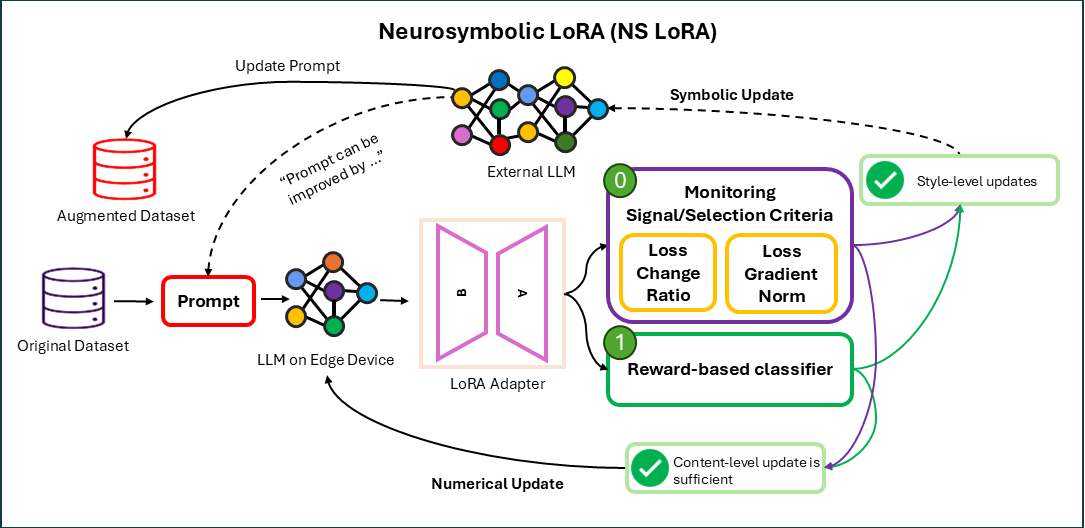
AAAI 2026 NeusymBridge Workshop (Oral)
|

|
COLM 2025
|
|
COLM 2025
|
|
|
CVPR 2025 AI4CC Workshop (Best Paper Award)
|
|
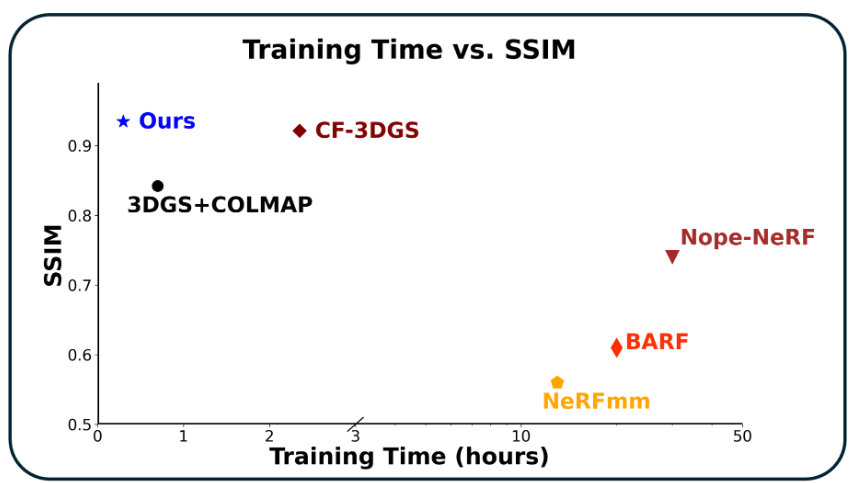
CVPR 2025
|
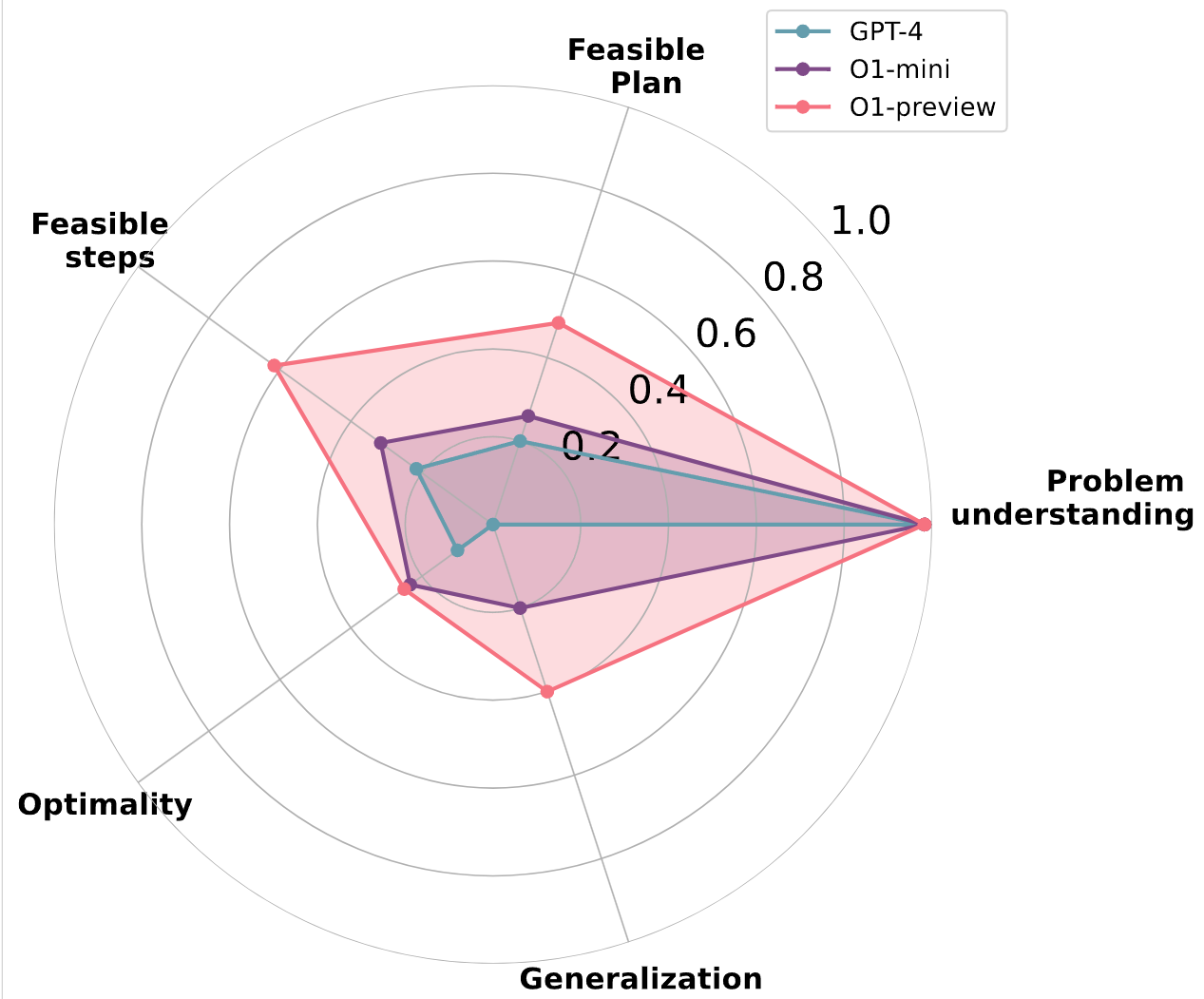
|
NeurIPS 2024 Workshop on Language Gamification
|
|
NeurIPS 2024 (Spotlight)
|
|
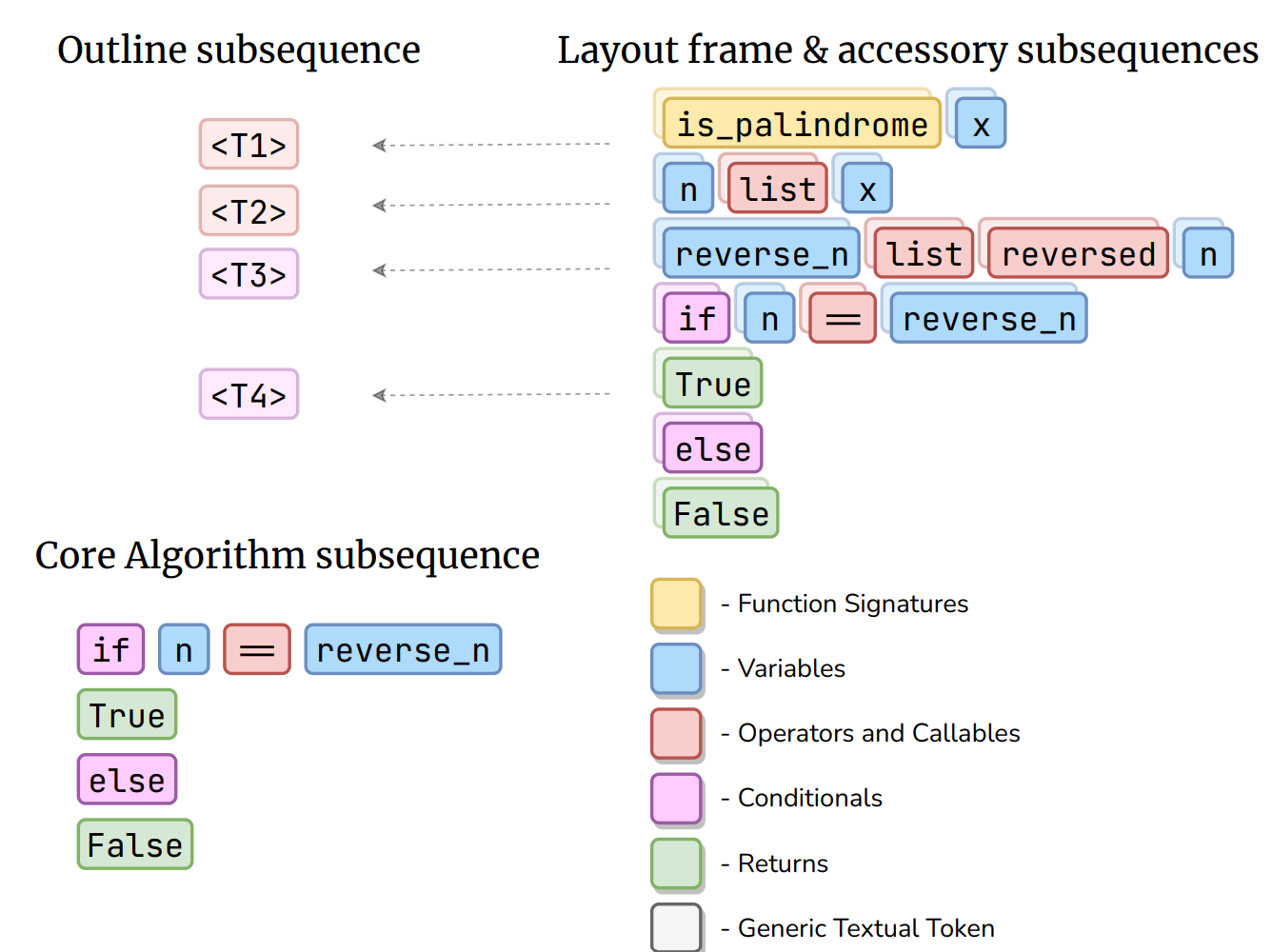
|
IEEE TPAMI 2024
|
|
Preprint 2024
|
|
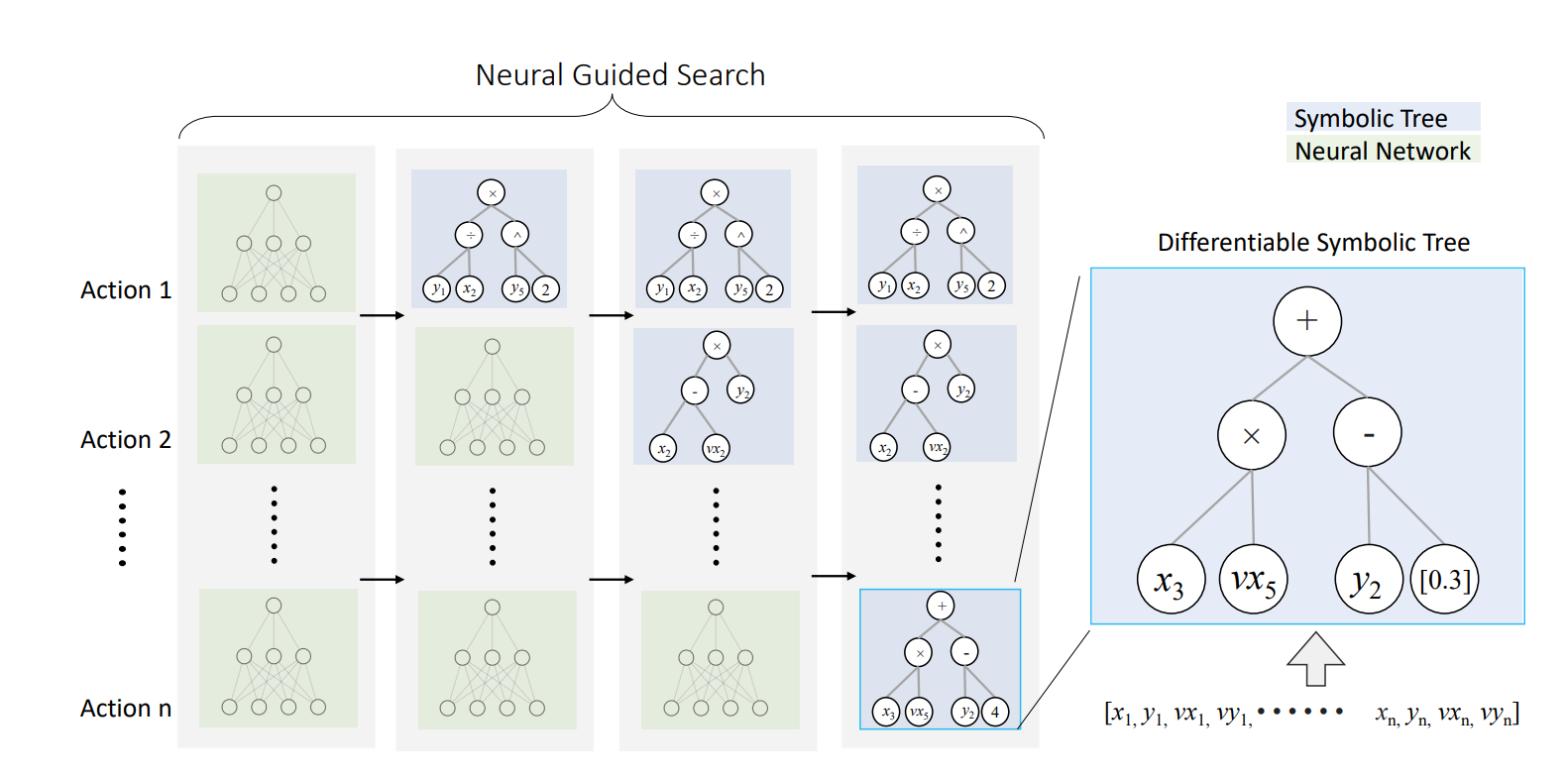
|
ICML 2023
|
Experience
University of Texas at Austin
Mar 2022 – PresentResearch Assistant, VITA Group
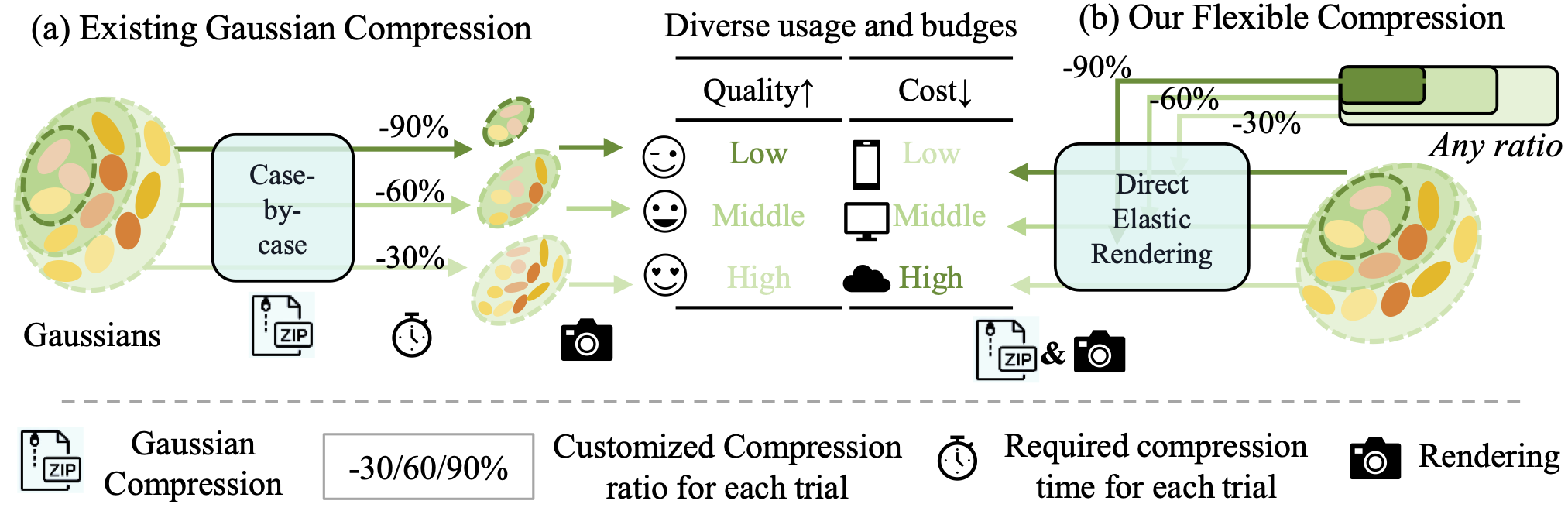
- 3D Gaussian compression achieving 15x reduction (400+ GitHub stars, NeurIPS Spotlight)
- Transformer-based language model for syntax error-free Python code generation (ICML)
- Symbolic visual RL with neural-guided differentiable expression search (TPAMI)
Sony
May 2025 – Aug 2025Applied AI Research Intern
- Compression and speedup of 3D Gaussian Splatting
SparkCognition
Jun 2022 – Aug 2022Machine Learning Engineer Intern
- Dual-layer classification for malware detection; 95% precision on unseen malware
- Feature pruning reduced runtime by 40%; Kubernetes training reduced time by 30%
Education
University of Texas at Austin
2022 – PresentPh.D. in Electrical & Computer Engineering, advised by Prof. Atlas Wang
University of Texas at Austin
2018 – 2022B.S. in Computer Science & B.S. in Mathematics | GPA: 3.78/4.0
Services
- Competition Organizer: MindGames (NeurIPS 2025)